Copy detection
Copy detection is the task of matching modified copies of images or videos.
Copy detection systems are critical components of large scale content moderation systems, allowing automated systems to identify copies of content that human moderators have previously taken down.
These technologies are widely used to fight child exploitative imagery. They are also useful to moderate problems that are challenging to identify without human judgement, such as misinformation.
Visual Copy Detection Workshop (VCDW) CVPR 2023
I'm a lead organizer of the Visual Copy Detection Workshop to be held at CVPR 2023 in Vancouver. This workshop will host presentations by Video Similarity Challenge participants, as well as invited talks on copy detection methods and use cases.
Video Similarity Challenge 2022-2023
The Video Similarity Challenge has launched!
This challenge is similar in spirit to the Image Similarity Challenge, adapted to the video domain. Participants must predict matching segments between query videos and a database of reference videos. Predicted segments must be temporally localized within each video.
This challenge studies partial video copy detection end-to-end, including the search step.
SSCD CVPR 2022
A Self-Supervised Descriptor for Image Copy Detection presents our SSCD fingerprint model.
This work adapts contrastive learning to the task of copy detection, and demonstrates how an entropy regularization technique significantly improves copy detection accuracy.
This work highlights important tradeoffs between semantic (i.e. linear classification) and copy detection accuracy.
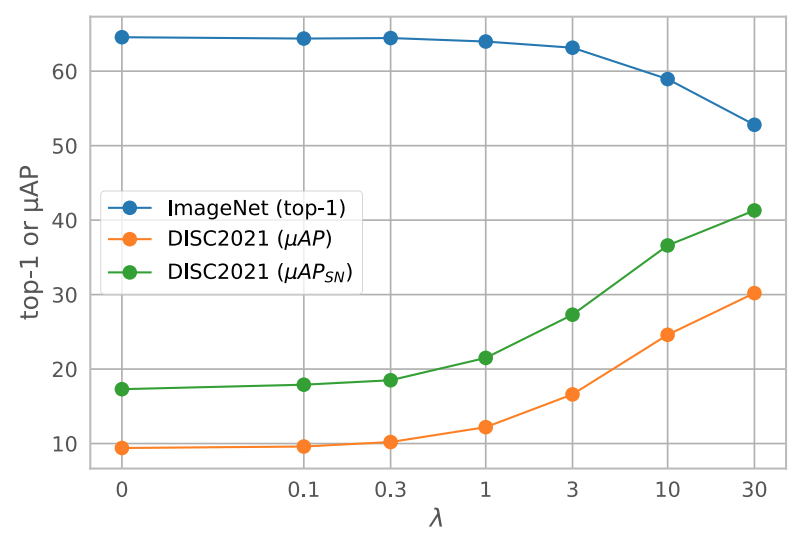 As the strength of entropy regularization (
As the strength of entropy regularization (
A production system based on an earlier version of this work, SimSearchNet++, is deployed on Facebook and Instagram.
See the open source SSCD codebase with released model weights, to reproduce both training and evaluation of our method.
Image Similarity Challenge NeurIPS 2021
The 2021 Image Similarity Challenge (ISC; see also the dataset paper) was an image copy detection challenge using a new dataset, DISC2021.
The dataset features a large dataset with robustly transformed matches. The challenge uses a needle-in-haystack setting inspired by real production systems, where most queries have no matches in the dataset.
 Example matches from the Image Similarity Challenge.
Example matches from the Image Similarity Challenge.